數據科學家/資料分析師 面試經驗分享 Data Scientist/ Data Analyst Interviews Experience

在經歷了三次不同階段的求職,我想在這邊彙整我從2018年至今的面試經驗及技巧分享。這次求職的過程中,我剛好被問到和我2018面試泰國Agoda的Data Analyst職位時一樣的問題;而在回答的同時,我清楚感覺到自己和當初的差別。儘管當初的回答並沒有不好,但我知道如何更有系統、規模化的方式來處理問題以及表達給面試官我的方式,也激發了我想把過去三次求職的經驗分享在這邊給大家。
After experienced three job searchings, I would like to summarize and share my interviews experience since 2018. I happened to have the same question I was asked back in 2018 when I applied for Data Analyst role at Agoda Bangkok in my interview this time.
Even though I think I did a great job back in 2018, I can tell how much I grow since then because I can solve the problem more systematic and with a way that can scale up meanwhile clearly deliver my ideas to the interviewers. And this inspired me to document and share my interview experience here with you.
由於我面試的職位大多數需要英文能力,因此接下來的紀錄我會大多數以英文描述並簡略用中文補充。
Behavior Questions
我會專注在申請資料科學相關職位會遇到的問題而跳過那些所有職位都可能遇到的一般問題。
I’ll focus on the behavior questions for data science roles instead of going through general behavior questions.
Tell me about a project you’ve done:
This is a great chance to show interviewers how you can fit into this role. Thus, it’s critical for you to understand the job description and requirements for this role. So that you can talk about a project that empowers you as a competitive candidate for the role.
For example, if I’m applying for a Data Scientist role which may need software development skills and some basic research experience, then I’ll have an answer like below:
I would like to share a project of developing a Python library in my team. I initiated this project to automate data collection, data preprocessing, and modeling; basically a ML pipeline but more flexible for putting them into different modules so that users can just use any part of it.
In our team, we need to write hundreds lines of code to connect to Hive and setting for fastest data collection, thus I have the idea to develop this library so that we can standardize it once and only need to run a few lines in the future. And my team and I further research on how we do data imputation for better model results and analysis interpretation. This Python library improved code efficiency by 20 times for reducing 95% of codes and data collection time consumed
By above story, I’m trying to let interviewers know:
- Experience of software development, ML pipeline building, and data imputation research
- Briefly mention about teamwork, initiating projects, simplifying tasks
- Some quantified results as productivity improvements
Analytical Case Questions
分析個案問題主要專注在看你如何評估、解決一個真實案例,是否能系統化或有效率地找出問題要點及分析的方向。在這邊推薦Cracking the PM Interview這本書,裡面有很多相關面試題目及技巧的分享!
This part is to test your problem solving skills; how you will evaluate the situation and tackle the problem with systematic and effective method to find root cause. I highly recommend a book called “Cracking the PM Interview” which is written by the author of “Cracking the coding Interview”. The book shared a lot of case interview questions and how to solve it.

If the sales of XXX products down significantly today, what will you do?
Mistakes I used to have is jumping to conclusions, trying to find the reasons directly. However, after interviewing for some roles at Google, I learn to ask clarification questions first, make assumptions, structure analysis plan, evaluate pros and cons, then have a short wrap up.
First, I would like to confirm if might be data inaccurate issue. Maybe it’s because some data is missing. And then I assume I have all traffic data so that I can build a funnel reports to compare if the conversion rate of any stage is different from usual.
If there is any specific conversion rate down in a stage, then we can further dive deep to see if there’s a feature error or function down. If not, we can consider if it’s overall traffic down or external factors like competitors’ move. Using this way, we can have an idea either it is an internal issue or external issue to further dive deep.
我會在腦中擬一個樹狀是非圖去從問問題、假設情況、分析計畫到總結等;盡可能地把重點提及但精簡,讓面試官追問再來進一步深入解釋。
I’m structuring a binary treemap with each layer as question, assumption, analysis plan, etc. Using this way, I have a clear plan to handle follow-up questions. And I try to have a simple plan and let interviewers ask follow-ups and I can further explain my thoughts on specific part.
Technical Questions
我把技術性問題分成下列五種:資料庫語言(SQL)、演算法(程式設計)、機器學習相關、儀表板設計、系統設計。
I separate technical questions into five fields: Database (SQL), Algorithms (Programming), Machine Learning related, Dashboard Design, System Design.
SQL
我大部分面試遇到的SQL問題最多就到這個難度,因此我會用這個例子來示範我怎麼解題。
Typically, the most SQL questions I had in interviews at most this level. Thus, I’ll use this one as an example of how I will solve it with query written below.

What’s the most frequent purchased items for each customers?
Required columns: customer_name, item_name
The first question that comes up to my mind is if there are more than one products with same frequency, should we show all of them? If so, I’ll consider to use rank window function in my query. And do we want to list those customers who never purchased. Here I assumed not showing them.
And the next thing is to structure a few key messages in my mind and write it down as notes.
# Most frequent -> rank()
# For each customers -> Group by customers
# A subquery first for frequency ranking of item for each customersWith rank_temp as (
select c.customer_name as customer_name
,i.item_name as item_name
,rank() OVER(Partition by c.customer_name order by count(*)) as ranking
from Order as o --key table for calculating purchase frequency
inner join Customers as c
on o.customer_id = c.customer_id
inner join Item as i
on o.item_id = i.item_id
);select customer_name, item_name
from rank_temp
where ranking = 1
To avoid only showing one item when there are actually multiple items with highest frequency, I use rank window function in my first subquery. With that, I’ll get ranking of each item for each customer. Then, in the next step I can use where clause to filter.
This is a simple example for entry level data role to test SQL capability. For the experienced role with a bit more advanced test, I’ve encounter some questions like below:

Most of the advanced questions, there’s only one table and you need to self-join to get a temp table for further calculation. And another type is also only giving you one table. But you need to use LEAD or LAG window function to get temp table for calculation. Therefore, I would suggest you study self-join and window functions to prepare for an experienced role.
Programming
這部分主要考程式設計的能力,題目主要跟LeetCode的演算法題目相似。在Data Scientist的職位中比較需要軟體開發能力的職位才需要,但這類題目大多涉及資料結構等概念,雖然在工作中用到的機會比較少,但對於電腦科學的理解還是些許幫助到工作上的思考能力。
This part is for testing your programming skills. It’s mostly coming from the algorithms questions on LeetCode. This kind of assessment is only required for those Data Scientist roles that might work on software development.But since the questions are covering data structures and other computer science knowledge, it can still help you on work a bit for programming design.
Given a list of sorted integers, can you modify the list by only including non-duplicate items?
Ex: input=[1,1,1,2,2,3,4,4,5]; output=[1,2,3,4,5]
The most special part of this question is it ask you to modify the given list. Not just output another list with answer. Therefore, we need to come up with a solution that drop duplicate out of given list.
# Programming language: Python 3# Requirements:
# Output need to be unique item only
# Modify the given list instead of return a new list
# List is sorteddef drop_dupliates(input):
i = 0
while i <= len(input)-2:
# minus 2 for index start with 0 and we are doing i+1 below
if input[i] == input[i+1]:
# Ex: input[0] == input[1] => 1 == 1
# If duplicate, pop out duplicate
input.pop(i+1)
else:
# Else execute next comparison
i += 1
return input
I’m basically doing comparison one pair at a time, starting with index 0 and index 1. Once found duplicate, drop the duplicate items. Until it’s not matching anymore, then move to next index.
And I use pop function so that it’s modified the input list so that even if we don’t return input, we can call the input list and found it’s already well-modified.
However, this is an acceptable answer, but not optimal because of the time complexity. Below is how we can further improve it.
# Programming language: Python 3# Requirements:
# Output need to be unique item only
# Modify the given list instead of return a new list
# List is sorteddef drop_dupliates(input):
read_idx = 0
write_idx = 0
n = len(input)
while read_idx < n:
while 0 < read_idx < n and input[read_idx] == input[read_idx-1]:
read_idx += 1
if read_idx < n:
input[write_idx] = input[read_idx]
write_idx += 1 read_idx += 1 del input[write_idx:] return input
Because in my previous solution, I pop each duplicate items once found. However, it can be execute once together for the same value. Therefore, we assign another two variables as read_idx and write_idx to make it more time efficient.
This is a question around easy-to-medium level, while there are many hard problems on LeetCode. If you are applying for a company like Google who is famous for asking these questions, I suggest you to practice as much as possible on LeetCode and other website.
Machine Learning related
Here is the section of knowledge questions about Machine Learning. From feature engineering, feature selection, and model evaluation; these simple questions to overfitting, regularization, and exploding gradients; these advanced knowledge.
There isn’t a good way to prepare for this part but walk through interview questions online one by one to make sure you know most of them. I suggest you can read through this article by Terrence Shin. He listed out a great amount of and great variety of different Data Science interview questions.
Dashboard Design
This part is more focus on business intelligence and data visualization. The foundation is based on how you choose the way to display key information. And the main assessment is about how you structure dashboard and why you design it in this way. What your clients (business stakeholders) can learn from this dashboard?
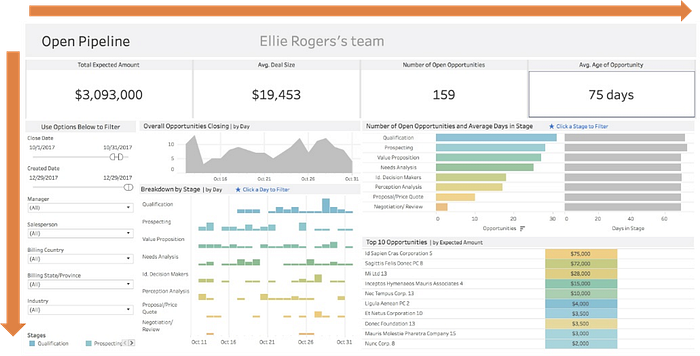
I’ll skip the chart type choosing part and go for the dashboard design. The key principle is how your clients read. Like the UX research, users read left to right and up to down in a route of Z shape. Therefore, I suggest you can go from general to specific. Putting general figure and metrics on the top, like DAU (Daily Active Users), GMS (Gross Merchandise Sales), etc. Then, all the parts below is for users to know how things change from time to time and maybe some reasons of changing.
Taking E-commerce industry for example, I’ll put sales, WoW (week over week), etc; on the top. Then, followed up with a sales trend by day below. And sales by each different type of products information (consumer electronics, furnitures, clothes) for users to know which part of sales is growing while others are decreasing.
There isn’t a specific best way to choose what information you put in the dashboard. It’s mostly based on your understanding of the industry and a core design strategy to put charts together in an understandable way.
System Design
System Design is also only required for those roles who need to work on infrastructure setup. For example, you’re implementing a production code like recommender system, search engine, or sometimes a business intelligence tools; then you need to define what data you need to collect, what data transformation will be needed, how to measure and monitor the performance of this system, and how you could continuously improve the system.
The field may involves MLOps (Machine Learning Operation) and some Data Scientist expertise, or even some DevOps (Development Operation). However, I suggest you focus on the requirements of the role to prepare for it.
I will suggest you can read through some articles from Netflix, Uber, Airbnb tech blogs to have a sense of how they implement things when they are developing a system.
Summary
雖然還有許多這篇文章沒有涵蓋到的部分,但以上幾種題型是我覺得比較好準備且面試幾乎都會問到的題型。準備面試最重要的還是聚焦在職位的要求上;因此,我會建議在準備的時候可以不斷地回顧職位的描述和要求來確定自己現在有回答相關問題的能力,並想想針對申請的公司產業還有部門,自己可以有怎麼樣的貢獻及應用,祝大家面試順利!
另外,我的分析課程在Udemy上線了!如果想瞭解更多關於分析以及分析工具、場景及方法的話,歡迎使用 I-WANT-DATA 的折扣碼購買!
Though there are still some parts that are not covered by this article, I try my best to cover those questions that we can prepare and mostly got asked. The key to prepare for interviews are still focusing on the job description and requirements. Therefore, I would suggest you to go back to the job description again and again when you are preparing for an interview. Make sure you have the knowledge to answer the corresponding questions and think about how you can contribute or what applications can be built for the industry and the team. Wish all of you luck in your job hunting!
If you want to learn more, please find my analytics course on Udemy. You can use coupon code I-WANT-DATA to get discount. Look forward to seeing you in the course!
